After five memorable years, my time at PwC has come to an end. I truly appreciate the opportunities and trust my colleagues and clients gave me — while I completed my transformation from research scientist to management consultant. My contribution to expanding the footprint of technology consulting, building trust in society, and solving important problems is something I’m proud of.
Now, the time is ripe for me to embark on a new professional journey. Today, I have started as a Principal at BCG Platinion — the technology consulting practice of Boston Consulting Group — where I will work with technology strategy, architecture, and governance in a more international environment. I’m excited by this opportunity and look forward to working globally with new colleagues and clients! Feel free to get in touch if you want to know more about what we do.
I recently got certified in Microsoft Azure Fundamentals and AWS Certified Cloud Practitioner. Hoping to help others who plan to do the same, I wrote an article on LinkedIn on how to get certified in two weeks. Your feedback is welcome!
A few of you noticed that I disappeared from Facebook, and asked me if everything is fine with me. Let me start by reassuring that everything is fine with my loved ones and me, both in Norway and Italy. That said, the reason why I deleted my Facebook account is that I cannot stand the disinformation and divisiveness on my feed anymore.
The Covid-19 pandemic has led to a new wave of conspiracy theories: from 5G antennas transmitting the virus via radio waves, to Bill Gates having engineered Covid-19, to the evergreen new world order orchestrating all of this. The echoes of the Brexit referendum and the last U.S. presidential elections are not hard to spot. It is the pitting of “skepticism” against “experts,” and of “people” against “elite.”
While conspiracy theories have long existed, Facebook and other social media have accelerated their circulation. Moderating content after it is shared thousands of times is insufficient. Curating knowledge before it is shared is just as crucial to contain disinformation. But the tech giant is failing at it spectacularly.
I was naïve enough to hope that the Covid-19 pandemic would restore some trust in reliable, fact-based sources of information. I could not be more wrong.
Facebook has known about this for a while. “Our algorithms exploit the human brain’s attraction to divisiveness,” read a slide from a 2018 presentation. “If left unchecked,” Facebook would feed users “more and more divisive content to gain user attention and increase time on the platform.” Nevertheless, Facebook shut down the efforts to make the site less divisive.
Four years after the Cambridge Analytica scandal, and six months after the start of the Covid-19 pandemic, very little has changed. Despite multinational companies now pulling ads from Facebook over inaction on hate speech, the tech giant is still doing too little to prevent disinformation and divisiveness. And what many people do not seem to understand is that this is bigger than any of us.
The president of the most powerful country in the world is an anti-intellectual who suggests curing Covid-19 with disinfectant injections and brags about his “tremendous job” in handling the pandemic, despite the U.S. topping all charts about infections and deaths. The silly movie Idiocracy from 2006 does not seem so unrealistic anymore. Before you realize it, another representative of the Dunning–Kruger effect could be in charge of your country.
Now, if this doesn’t scare you, I don’t know what will.
Stopping using Facebook will not help fighting disinformation and divisiveness. Quite the contrary. But at least I will avoid everyday frustrations and invest my time more wisely.
The COVID-19 crisis has pushed a digital transformation in record time. Traditional work dynamics are gone, and many of us see now our homes as where we work.
We have never been more dependent on our employer’s IT solutions. While some tackle the transition to remote work without disruptions, others experience frustration with outdated devices and unstable services. This frustration gets compounded by dealing with non-technical issues such as suboptimal ergonomics or demanding children.
Most people are used to a seamless user experience in their private lives. Despite a global explosion in service demand around the Internet, they continue to have video calls on FaceTime, share photos on Instagram, and watch movies on Netflix, exactly like before.
Employees expect comparable user experiences in their working lives. If it is poor, some may use private devices and services as alternative IT solutions. This workaround is known as “shadow IT” and it can compromise the organization’s compliance and security. The consequences from shadow IT can quickly become expensive.
A sustainable IT architecture is crucial for realizing an effective digital workplace. It must balance scalability, security, and user experience. Here is how you, as CIO, can move forward to provide a digital workplace to your employees:
1. Migrate from on-premises to the cloud
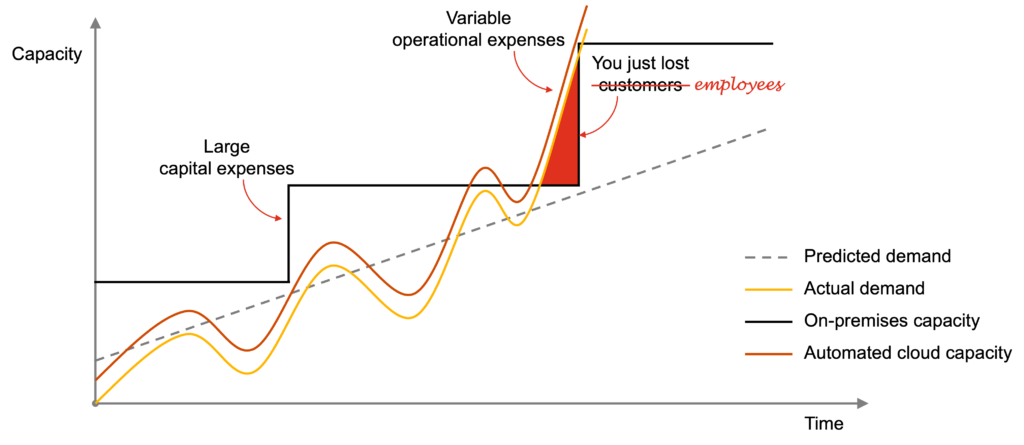
Your organization probably still relies on on-premises infrastructure to operate business services, as well as end-user services such as connectivity, communication, and collaboration.
One of the issues with on-premises infrastructure is that you have to purchase and install servers, storage, networking, and other computing resources to expand its capacity—a process that may take months in normal circumstances, let alone during a pandemic.
When the actual demand surpasses the available capacity, you have got a problem. The typical consequence is that you lose customers. In this scenario, you lose employees too, as they are unable to work.
Adopt hyper-scale infrastructure and software-as-a-service
The cloud offers hyper-scale infrastructure, which allows you to rapidly provision computing resources with minimal management effort.
When exploiting automation, the available capacity can automatically scale up and down based on the actual demand. In this case, you can cope with unexpected spikes with minimal downsides, such as losing employees on the way.
Microsoft with Microsoft 365 and Google with G Suite offer cloud-based collaboration platforms. Other software-as-a-service providers cover plenty of additional capabilities for a digital workplace. You may want to widen their adoption in your organization.
2. Switch from perimeter- to zero trust security
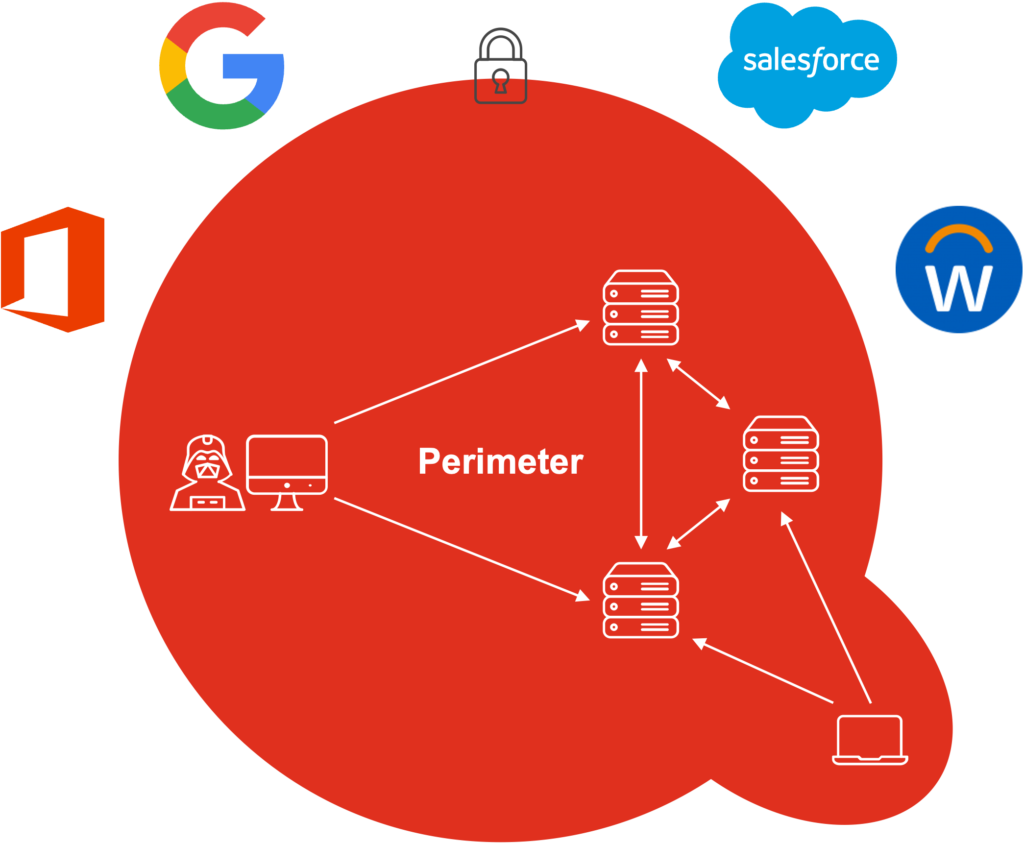
Your organization needs to protect business and end-user services through an adequate security model.
Not unlike a medieval castle, the perimeter security model relies on a secured boundary between the private side of a network, often the intranet, and the public side of a network, often the Internet.
Virtual private network (VPN), firewall, and other tools protected your IT environment from cyber threats relatively well during the ‘90s and 2000s, when you had few entry points for users and devices. However, these tools were not designed for your current IT environment, where you have heterogeneous users and devices, both on-premises and in the cloud.
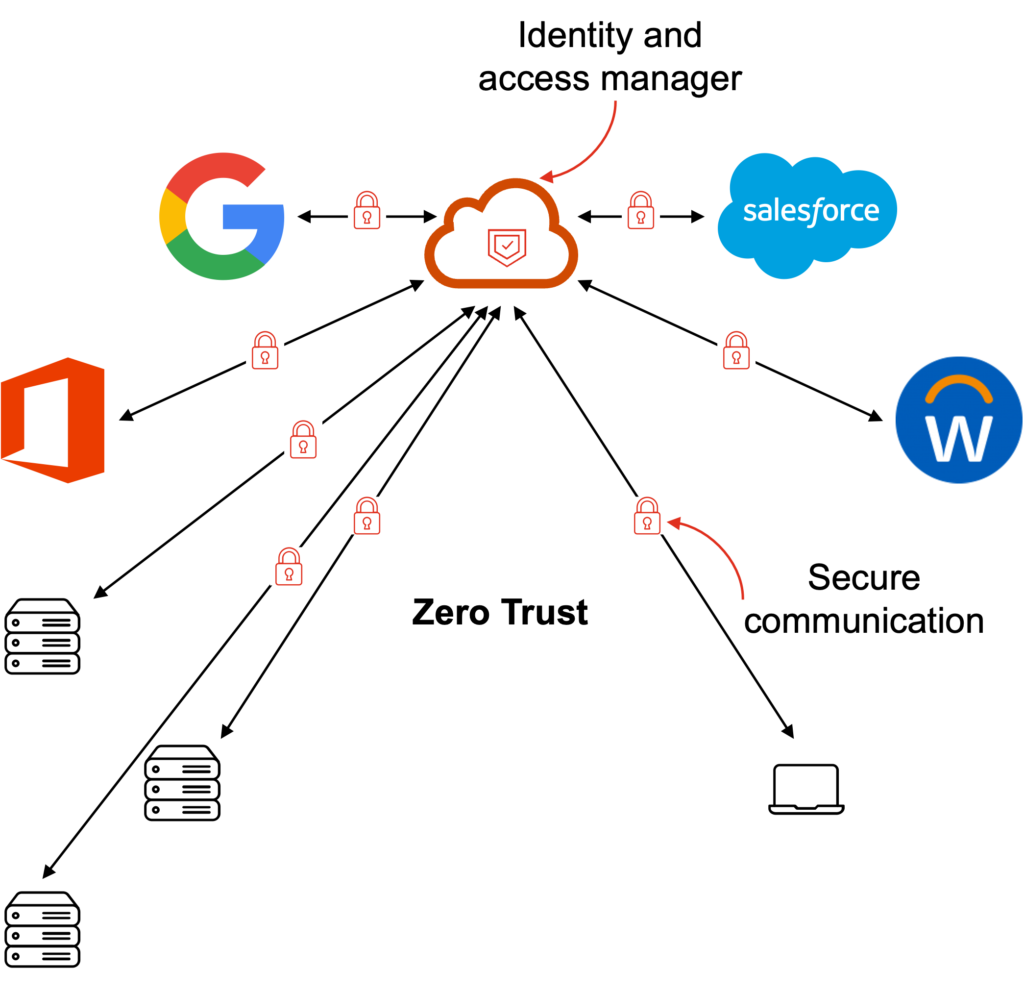
Authenticate, authorize, and verify all users and devices
The zero trust security model relies on the principle that you should not trust anyone, neither inside nor outside your perimeter. You should instead authenticate, authorize, and verify all users and devices attempting to access your systems.
Identity and access management (IAM), multi-factor authentication (MFA), unified endpoint management (UEM), encryption, and other tools are better suited for this purpose. These tools allow you to flexibly combine legacy systems on-premises and modern systems in the cloud with heterogeneous users and devices.
Microsoft, Google, and other major IT players recommend the zero trust security model. They adopt it in their own companies. You may want to accelerate its implementation in your organization.
3. Focus on the user experience
Your organization may have neglected the user experience of IT services. IT departments may offer employees a one-size-fits-all PC, while alternatives such as Macs and iPads may be non-supported options. Some business applications may have cumbersome user interfaces. Others may require employees to access outdated remote desktop solutions. Some communication and collaboration applications may provide redundant functionalities, which can leave employees unsure about when to use what.
Avoid shadow IT
If this goes too far, employees could feel like the IT department provided them with tools that diminish rather than enhance their productivity. Their frustration could even lead them to shadow IT, with potentially severe consequences.
There are more efficient ways of working, which can raise employee engagement. To succeed, you need to provide a quality of service comparable to the ones of Apple and Google, whose devices and services “just work.” In other words, you need to provide state-of-the-art hardware, software, and underlying IT architecture.
A digital workplace requires a comprehensive approach to delivering a consumer-oriented IT environment, where the technology is continuously improved, and the workforce is frequently upskilled.
This approach is ambitious, and is going to cost—but it may be the most forward-looking investment you can make.
A shorter version of this article was published in Norwegian in Teknisk Ukeblad on May 2020.
Imagine if the greatest technological inventions in history—such as the steam engine, electricity, or the Internet—had been left stranded in research laboratories and never transferred to society. The world would look radically different today. There are plenty of untold stories of inventions that never saw the light of day, and many potentially breakthrough ideas fall into the so-called technological “valley of death” due to a gap between academic research and industrial commercialization. This is a missed opportunity for economic and social progress. In this article, I offer five actions for academia and industry to bridge the valley of death and co-create innovation.
In recent years, the public has often associated technological innovation with the most successful private companies in the world, such as Apple, Google, and Microsoft. These organizations have built an entrepreneurial culture characterized by networks (rather than hierarchies), empowerment (rather than control), and agile execution (rather than rigid planning). While these factors play a role in fostering technological innovation, one of the fundamental drivers remains technology research. Unlike traditional research—which aims at obtaining new knowledge about the real world—technology research aims at producing new and better solutions to practical problems.
Consider the disruption brought to the smartphone market by the iPhone. The user experience of Apple’s first smartphone was undoubtedly superior to the competition, and this was probably the recipe for its success. However, a significant portion of the technologies leveraged by the iPhone was originally conceived in research conducted by the public sector. The programming languages used in the iPhone, for instance, have roots in the research conducted between the 1950s and the 1980s by multiple organizations worldwide, including the Massachusetts Institute of Technology and the Norwegian Computing Center.
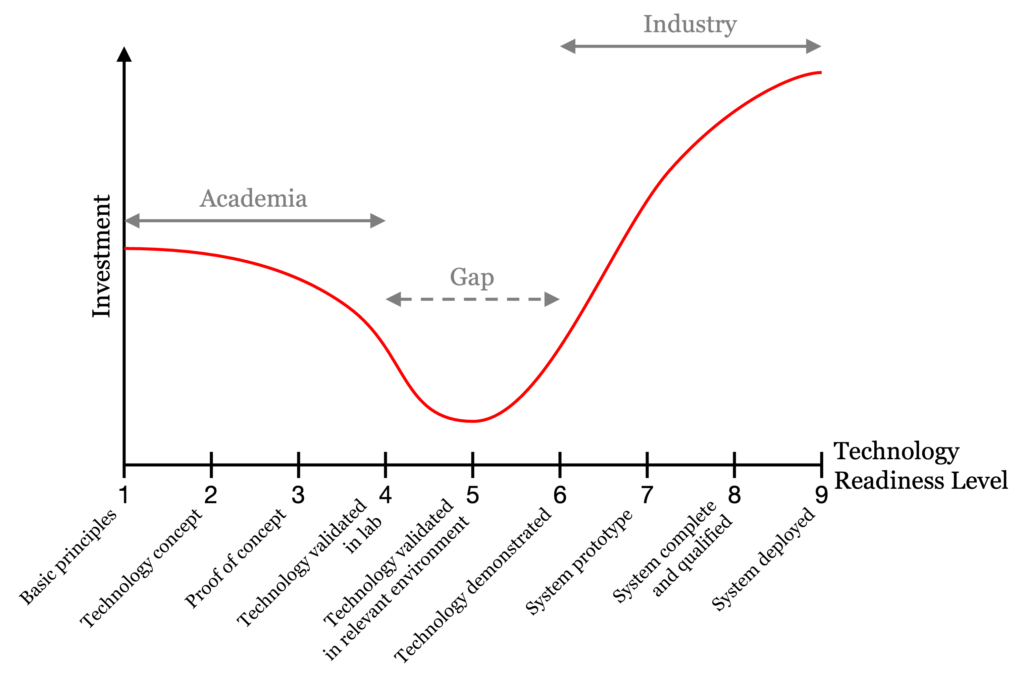
The journey of new technology from research to commercialization goes through a number of technology readiness levels (TRLs). These levels were developed at NASA between the 1970s and the 1990s, and indicate the maturity of technologies. The latest version of the scale from NASA includes nine TRLs and has gained widespread acceptance across governments, academia, and industry. The European Commission adopted this scale in its Horizon 2020 program.
The nine technology readiness levels are:
Basic principles observed
Technology concept formulated
Experimental proof of concept
Technology validated in a lab
Technology validated in a relevant environment
Technology demonstrated in a relevant environment
System prototype demonstrated in an operational environment
System complete and qualified
System deployed in an operational environment
Some tech giants are large enough to fund research units and work at all levels of this scale, but most companies cannot afford the high investments and specialized competencies this approach requires. Either way, in today’s dynamic and volatile markets they have to aim at doing the disrupting in order to avoid being disrupted. Companies that cannot afford research units have to innovate by relying on research conducted elsewhere, and the natural candidate is academia.
The question is: at which TRL does academia transfer technology to industry?
Academia tends to focus on TRLs 1–4, whereas industry prefers to work with TRLs 7–9, rarely 6. Therefore, TRLs 4–6 represent a gap between academic research and industrial commercialization. This gap is colloquially referred to as the technological “valley of death” to emphasize that many new technologies reach TRLs 4–6 and die there.
The issue of the valley of death has been studied extensively, and the scientific literature offers several proposals for bridging the gap. With the aim of facilitating technology transfer, some research organizations have focused entirely on technology research in the last 50 years. The Fraunhofer Society in Germany and SINTEF in Norway are notable examples. Still, these efforts have not entirely bridged the gap between academia and industry.
So, how can academia and industry bridge the technological valley of death and co-create innovation?
1. Academia and industry should better understand each other’s culture
To paraphrase a well-known proverb: academia is from Mars and industry is from Venus. This is not only reflected in the way people work but also the way people communicate and possibly dress. The following statements are deliberate exaggerations, but they allow pondering on the cultural differences in the status quo. Academics have a long-term horizon; practitioners have a short-term horizon. Academics think (often critically); practitioners do (often routinely). Academics are pedantic; practitioners are practical. And the list could go on and on… Note that academia is not superior to industry, and industry is not superior to academia. They are just different, and this diversity can be healthy to drive technological innovation. Understanding each other’s culture is of paramount importance to improve the collaboration across teams on both sides.
2. Academics should better understand real-world industrial challenges
Academic research tends to aim at academic communities. As a consequence, an increasing number of research papers do not have adequate industrial relevance. As Lionel Briand—a recognized professor and researcher in software engineering—recently put it: “If a solution to a problem is not applicable and scalable, at least in some identifiable context, then the problem is not solved. It does not matter how well written and sound the published articles are, and how many awards they received.” Academics should join industrial fora (conferences, seminars, etc.) more often in order to understand real-world industrial challenges.
3. Practitioners should stay up-to-date with the state-of-the-art
The fact that certain research papers do not have an adequate industrial relevance does not mean that industry cannot resort to the scientific literature to find answers to its questions. Quite the contrary: the answer is often available in peer-reviewed journals, many of which are openly accessible. Consider, for instance, password expiration policies. There is evidence that changing passwords on a regular basis does more harm than good since it drives users to new passwords that can be predicted based on previous passwords. Nevertheless, most IT departments keep enforcing this policy rather than adopting modern authentication solutions. Imagine if medical doctors would neglect research results in the same way… Unrealistic, right? Practitioners should join academic fora and consult the scientific literature more often in order to stay up-to-date with the state-of-the-art.
4. Industry should hire more PhDs
Besides the qualities that may make PhDs more valuable than other job candidates, people who invested at least three years of their lives researching in academia know the environment well enough to foster: the identification of research trends, the understanding of research results, and—most of all—the collaboration with academia. In the process of academic inflation given by a steadily increasing number of doctorates every year, the academic pyramid is getting wider, and not all PhDs have the opportunity to access permanent academic jobs. Industry has the chance to capitalize on this trend by hiring more PhDs.
5. Academia and industry should conduct more joint research projects
Academia and industry can organize their joint research projects based on two models: 1) bilateral collaboration, where both academia and industry provide their contribution in the form of cash or in-kind, or 2) research projects partly funded by governmental organizations. The latter option may be better suited in case of tight budgets and lack of experience with this kind of collaboration.
Research is by definition unpredictable, and research projects cannot be assessed based on cost-benefit analysis. Nevertheless, statistics on past research projects show high long-term return on investment. The European Commission and the Norwegian Research Council (as well as other governmental organizations around the world) have a wide variety of research programs in a heterogeneous set of domains, which should be sufficient to cover the needs of most establishments. The competition for accessing funding has increased dramatically in the last decade, so the stakeholders should pick their partners and prepare their funding applications carefully.
While the success stories of fruitful collaboration between academia and industry are encouraging, there is a lot of untapped potential in the synergy between the two. Understanding each other’s culture, joining each other’s fora, leveraging PhDs’ competence and skills, and conducting joint research projects are certainly steps in the right direction. Technology has been responsible for tremendous economic growth and increased quality of life for billions of people. Bridging the technological valley of death is definitely worth solving, regardless of whether the ultimate goal is an increased profit or the greater good.
A shorter version of this article was published in Norwegian in Teknisk Ukeblad on February 2019.